Data Warehouse Architecture for Mobile App Review Analysis
Background
In the early days of business, there is only one kind of database, transactional database. As the business grows, the requirements to support data analysis emerge. To do data analysis, we can make use of data warehousing architecture. Data Warehouse is a collection of integrated databases designed to support the DSS (decision support system) function1 and are considered as a core component of BI (business intelligence)2.
In this blog post, I will present my architecture designed to be used for mobile app review analysis requirements.
Data Layers
Data in the data warehouse comes from at least one source, whether operational/transactional database, flat files, or any other data repository. The figure below shows the basic data warehouse architecture.

Figure 2.1 Basic Data Warehouse Architecture
As can be seen from the previous image, there are several layers of repository. While there might be different warehousing architecture, the principles of data layer still persist. Some might skips warehouse layer entirely and directly connects staging to the data marts.
The first layer is of course the data source layer. The source layer can be made up of several operational systems, flat files, or even web API. The sources in this layer may come from internal or external third-party system. Due to the difference in data types, schemas, and semantics, the data from this source layer is considered “dirty”. By dirty we means that this data is not ready for analysis, especially aggregated analysis.
So the next layer, staging, is used as temporary repository for data cleaning and processing. This staging area collects data from source layer and prepare it for analysis.
The third layer is warehouse. While the data is already treated and prepared on the previous layer, this layer is used to construct a new OLAP specific schema called star schema. Basically we convert the structure of the data from the transactional model with focus on data normalization, streamlined storage, and write/update speed to the denormalized analytical model with focus on optimizing data reading.
A star schema is a collection of dimension tables and one or more fact tables2,3. The fact table contains transactional information while dimension table contains only master data2,3,4,5.
In the warehouse layer, we use the star schema to create a uniform and centralized data across the organization.
The data mart layer is optional in some cases. This layer provides easier access to data stored in data warehouse from different business areas. Data in this layer are in a ready-to-use format rather than the facts and dimensions table format in warehouse that needs to be joined together.
The last layer is presentation layer, where the consumer of the data is located. This consumer can be analytical tools like dashboard or BI systems, mining systems, or even regular user that access the data marts using query.
For the app review analysis, we will use all layers explained previously and are to be detailed in the next several subsections.
Data Source and Staging
The review data comes from two different sources, and both are external to the organization. To learn more about where the data comes from and what their schema looks like please visit my previous blog post, Scraping and Preparing App Review Data, that explain it in detail. The cleaning and treatment of the data is also explained in the post.
After preparing the data, now we need to change the schema to star schema which will be explained in the next subsection.
Warehouse Dimensional Model
The figure below shows the dimensional model of the warehouse layer for app review analysis.

Figure 2.2.1 App Review Dimensional Model
The dimension tables are suffixed with the _dim keyword while fact tables didn’t have any prefix or suffix.
Data Marts
Data in warehouse layer are then moved to data marts for specific use cases such as analysis and data mining. The figure below shows the data marts for app review analysis.
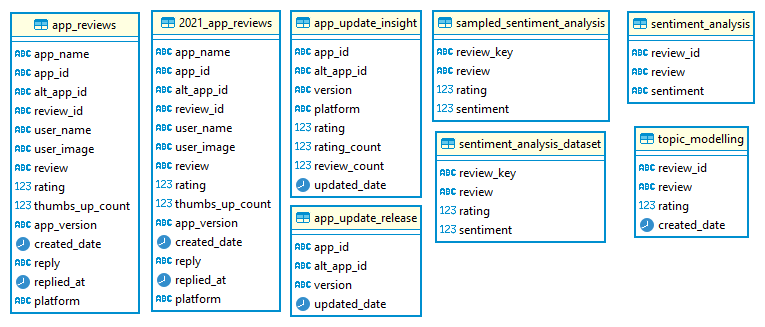
Figure 2.3.1 App Review Data Marts
Table app_reviews and 2021_app_reviews contains the reviews data and are used in dashboarding tools. Table sentiment_analysis_dataset and sampled_sentiment_analysis are used to train sentiment analysis while table sentiment_analysis is used to store the sentiment predicted by the ML model. Table topic_modelling contains training data for topic modelling.
Moving Data Between Layers
The movement path of data from source to the warehouse is called data pipeline. The act of moving data from one layer to another is referred to as Extract, Transform and Load, or ETL for short.
To configure the pipeline and run the ETL jobs, we use Airflow to monitor and execute our workflows. For more detailed information on the installation of Airflow please refer to my blog post, Running Airflow in Docker.
Here’s a snippet that shows how we move the review data from source layer to staging layer.
Summary
For conducting analysis on app reviews data, we construct data warehouse environment with 4 data repository layer: source, staging, warehouse, and data marts. The schema used in warehouse layer is star schema, it has two fact tables and five dimension tables. Data marts is also used here for analysis or mining with specific purpose and requirements.
The data is moved between layers periodically with an automated system, Airflow, that runs the workflows defined as DAG.
References
[1] Inmon, W. H. (2005). Building the data warehouse. John wiley & sons.
[2] Dedić, N., & Stanier, C. (2016). An evaluation of the challenges of multilingualism in data warehouse development.
[3] Cios, K. J., Swiniarski, R. W., Pedrycz, W., & Kurgan, L. A. (2007). The knowledge discovery process. In Data Mining (pp. 9-24). Springer, Boston, MA.
[4] Kimball, R., Ross, M., Thorthwaite, W., Becker, B., & Mundy, J. (2008). The data warehouse lifecycle toolkit. John Wiley & Sons.
[5] Jensen, C. S., Pedersen, T. B., & Thomsen, C. (2010). Multidimensional databases and data warehousing. Synthesis Lectures on Data Management, 2(1), 1-111.