E-commerce Data Analysis using Statistics and Machine Learning
Table of Contents ▾
- Background
- Data Engineer
- Data Analysis
- Data Science
- Summary
Background
“Data is the new oil.” - Wired.com
Pada tahun 2014, situs berita wired.com mempublikasikan sebuah berita dengan judul “Data Is the New Oil of the Digital Economy”. Judul ini seolah seperti memberikan otoritas kepada data untuk menentukan arah perkembangan ekonomi digital. Data memang memiliki sifat yang serupa seperti minyak. Ketika minyak masih dalam bentuk mentah jumlahnya sangat banyak, tetapi tidak bisa dimanfaatkan. Namun setelah melalui proses ekstraksi, pengolahan, dan penelitian pada akhirnya minyak dapat digunakan untuk bahan bakar, bahan produksi material seperti plastik, hingga produk-produk kecantikan. Data dalam bentuk mentah jumlahnya juga sangat banyak, namun tidak bermanfaat karena sulit untuk menemukan informasi yang berharga. Proses ekstraksi, pengolahan, dan analisis juga diperlukan untuk dapat menemukan informasi yang berharga pada kumpulan data.
Pengolahan dan analisis data dapat dilakukan secara manual oleh manusia. Jika data berukuran besar atau diperbarui dengan sangat cepat, proses pengolahan dan analisis yang akan memakan waktu yang lama. Pada kondisi seperti ini komputer adalah solusinya. Komputer dapat mengolah dan melakukan analisis pada data dengan sangat cepat dan akurat. Tentu, manusia masih memegang peranan penting untuk merancang alur dan prosedur pengolahan serta analisis yang dilakukan pada data. Namun dengan kecepatan dan akurasi komputasi yang dimiliki oleh komputer, beban pekerjaan manusia menjadi jauh lebih ringan. Proses analisis dengan memanfaatkan komputer ini disebut dengan istilah Machine Learning.
Informasi hasil analisis data kemudian digunakan untuk membantu dalam proses pengambilan keputusan, perencanaan, personalisasi, dan banyak lainnya. Pada konteks e-commerce keputusan yang dibuat meliputi ranah pemasaran, penjualan, pengiriman barang, hingga akuisisi pengguna.
Tahapan analisis data e-commerce yang saya lakukan dibagi kedalam tiga bagian. Bagian pertama adalah tahap data engineer untuk melakukan ekstraksi dan pengolahan data. Bagian selanjutnya adalah tahap data analysis untuk melakukan analisis data menggunakan grafik dan statistik untuk menghasilkan informasi yang bermanfaat. Tahap ketiga adalah data science untuk melakukan analisis menggunakan bantuan komputer. Ketiga tahapan ini tidak senantiasa dilakukan secara linear dan berurutan melainkan secara non-linear dan iteratif.
Data Engineer
Seperti yang sudah saya sebutkan pada bagian sebelumnya, data dalam bentuk mentah dianggap tidak berharga karena sulit untuk menghasilkan informasi penting dari jutaan angka dan huruf. Pada bagian pertama ini, saya akan memberikan treatment kepada data mentah untuk menghasilkan struktur dan hubungan yang lebih jelas.
Data mentah saya dapatkan dari file csv (Comma Separated Value) yang diberikan oleh mentor. Katanya sih data ini sengaja dibuat “kotor” sebagai bentuk tantangan untuk melakukan pembersihan atau pengolahan. Data tersebut merupakan data penjualan dari suatu e-commerce yang memuat informasi terkait pengguna, penjual, produk, pesanan, ulasan, dan pembayaran.
Pada bagian ini saya tidak memiliki urutan pengerjaan dengan jelas, namun yang pasti tahap data engineer ini saya bagi kedalam dua bagian yaitu:
- Konfigurasi source database, dan
- Pembangunan data warehouse
Source Database Logical Design
File csv tidak cocok untuk kebutuhan analisis dan akses data secara cepat dan kompleks. Oleh karena itu pada tahap pertama dalam data engineer ini saya akan membuat basis data untuk menyimpan data untuk kebutuhan pemrosesan. Keunggulan dari penggunaan basis data adalah kemudahan pengaksesan data, manajemen akses, dan kemampuan penyajian data dengan transformasi kompleks menggunakan SQL.
Sistem manajemen basis data yang saya gunakan adalah PostgreSQL versi 13.
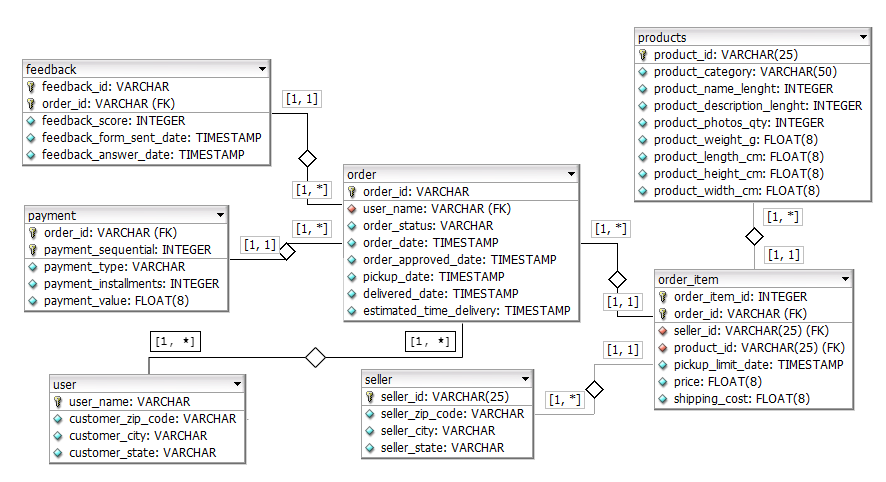
Gambar 1.1.1 Database ERD
Gambar 1.1.1 menunjukkan logical design dari basis data sumber. Keseluruhannya terdapat 7 tabel yang terhubung menggunakan asosiasi one-to-many yang dilambangkan dengan [1, 1] <-> [1, *] atau many-to-many yang dilambangkan dengan [1, *] <-> [1, *].
Data pengguna, penjual, dan produk disimpan dalam tabel user, seller, dan products. Tabel-tabel tersebut menyimpan informasi yang dapat digunakan untuk mengidentifikasi entitas yang satu dengan yang lain. Entitas ini nantinya yang akan digunakan sebagai “aktor” dalam transaksi dan disimpan dalam tabel lain sebagai foreign key.
Data transaksi pengguna disimpan pada tabel order. Tabel tersebut menyimpan informasi terkait status transaksi, tanggal transaksi, dan pengguna yang melakukan transaksi.
Dalam sebuah transaksi, pengguna dapat membeli satu atau lebih produk. Semua data terkait produk yang dibeli dalam satu transaksi disimpan dalam tabel order-item. Tabel order dengan order-item memiliki hubungan one-to-many dimana satu order dapat diasosiasikan dengan satu atau lebih order-item.
Saat melakukan transaksi, pengguna perlu membayar apa yang ia beli. Data pembayaran yang digunakan oleh pengguna disimpan dalam tabel payment. Tabel order memiliki hubungan one-to-many dengan tabel payment sehingga satu order dapat memiliki satu atau lebih pembayaran.
Setelah melakukan transaksi, pengguna dapat memberikan ulasan terhadap kualitas dari produk yang dibeli. Tabel feedback digunakan untuk menyimpan ulasan-ulasan dari pengguna. Tabel ini juga memiliki hubungan one-to-many dengan tabel order.
Pembangunan Data Warehouse
Setelah melakukan perancangan pada basis data sumber, langkah selanjutnya adalah pembuatan data warehouse.
Untuk keperluan analitik diperlukan suatu repository yang dapat menyimpan data secara historikal, berorientasi subjek, dan terintegrasi. Basis data tidak tepat digunakan karena fokusnya adalah untuk kebutuhan operasional. Data warehouse adalah pilihan yang banyak digunakan. Konsep dasar data warehouse yaitu:
- Berorientasi subjek: Artinya data warehouse memiliki fokus atau tema tertentu seperti sales, marketing, atau production.
- Terintegrasi: Data warehouse dapat menggabungkan data dari berbagai sumber dalam satu tempat dengan struktur yang telah disetarakan. Data mentah dapat berasal dari file json, csv, atau bahkan dari log suatu komputer.
- Historikal: Data warehouse menyimpan seluruh perubahan data yang terjadi pada sumber. Kebutuhan analitik untuk mengetahui kondisi masa lalu dapat diatasi dengan menggunakan data warehouse.
- Non-volatile: Operasi update jarang atau hampir tidak dilakukan sama sekali pada data warehouse. Apabila ada perubahan pada data sumber, data warehouse dapat mengatasinya dengan menyimpan sebagai data baru atau dengan strategi tertentu misalnya SCD (Slowly Changing Dimension).
Ralph Kimball, bapak data warehouse, menciptakan konsep pemodelan data warehouse yang dirancang khusus untuk memenuhi kebutuhan analisis data numerik seperti nilai, jumlah, berat, dan lainnya yang disebut dengan dimensional modelling.
Warehouse Dimensional Modelling
Bagian penting dari dimensional modelling adalah pembagian tabel kedalam dua peran yaitu sebagai fact table dan dimension table. Pembagian peran tabel ini mempermudah dalam proses pengambilan informasi dan untuk menghasilkan laporan.
Fact adalah ukuran atau metrik dari proses bisnis. Misalnya pada proses bisnis penjualan, maka faktanya adalah jumlah penjualan. Fakta ini dapat diberi dimensi untuk menghasilkan informasi tambahan. Seperti jumlah penjualan per bulan, jumlah penjualan per kuartal, atau jumlah penjualan pada wilayah tertentu.
Fact table adalah tabel yang berisikan setidaknya satu fakta, meskipun ada juga jenis fact table yang tidak memiliki fakta, dan dimensi sebagai konteks dari fakta tersebut.
Dimension table memberikan konteks terhadap kejadian-kejadian pada proses bisnis. Sederhananya, dimensi memberikan informasi mengenai siapa, apa, dimana, dan kapan dari fakta. Pada proses bisnis penjualan, dimensinya adalah:
- Siapa - Nama pembeli
- Dimana - Lokasi
- Apa - Nama produk
- Kapan - Tanggal dan jam
Dimensi pada tabel fakta tidak selalu memiliki semua komponen Siapa-Dimana-Apa-Kapan, namun idealnya semakin banyak informasi yang dapat ditambahkan maka semakin baik.
Data mart merupakan data warehouse yang lebih spesifik ke satu subjek misalnya sales, HR, atau marketing.
Tabel-tabel fakta yang saya buat dalam tahap ini adalah:
- Fact order
- Fact feedback
Data mart yang saya buat dalam tahap ini adalah:
- Data mart customer RFM
1. Fact Order
Penjualan adalah aspek penting pada e-commerce. Analisis penjualan bermanfaat untuk menilai performa periodik, memprediksi permintaan masa depan, dan untuk menyusun strategi pemasaran. Untuk mendukung analisis penjualan, saya membuat tabel untuk menyimpan fakta penjualan (Gambar 1.2.1).
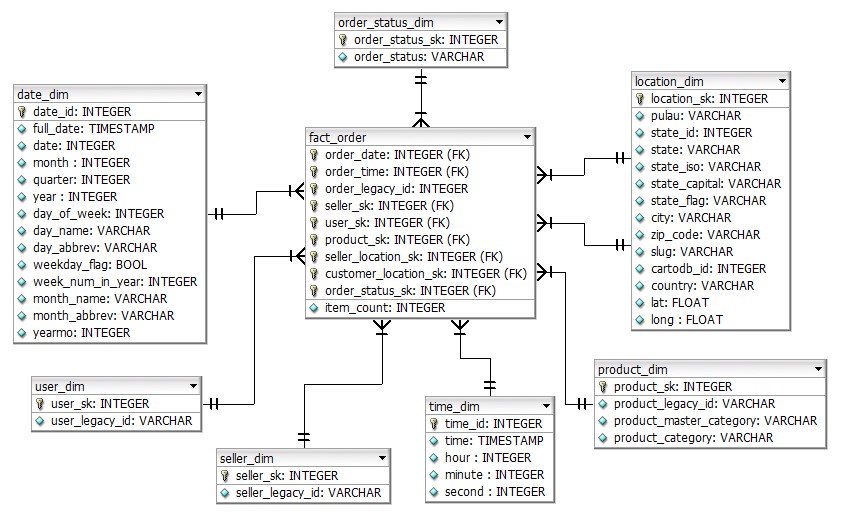
Gambar 1.2.1 Fact order ERD
Tabel fakta order ini digunakan pada bagian data analisis dan untuk melatih model machine learning jenis supervised learning.
Dimensi yang digunakan adalah tanggal dan jam pesanan, penjual, pengguna yang membeli, produk, lokasi penjual, lokasi pembeli, dan status pesanan. Dimensi-dimensi tersebut sekaligus menentukan granularity pada tabel fakta order ini. Sehingga granularity-nya adalah pada level produk dalam setiap transaksi.
2. Fact Feedback
Ukuran kepuasan pelanggan dari produk dan layanan yang diberikan pada e-commerce ini adalah ulasan. Pengguna yang kurang puas akan memilih untuk meninggalkan e-commerce ini. Sehingga penting untuk melakukan analisis terhadap ulasan pelanggan. Analisis tersebut ditujukan untuk mengetahui aspek apa yang perlu diperbaiki dari layanan ataupun produk yang ditawarkan. Untuk mendukung analisis kepuasan pelanggan, saya membuat tabel fakta ulasan (Gambar 1.2.2).
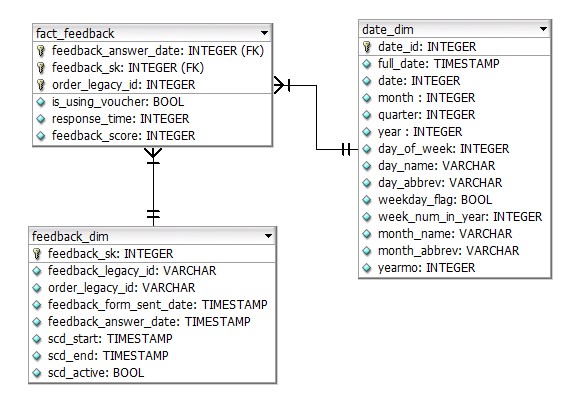
Gambar 1.2.2 Fact feedback ERD
Bagian data analisis selanjutnya juga menggunakan tabel ini untuk mengetahui pengaruh penggunaan voucher terhadap kepuasan pelanggan.
Dimensi yang digunakan adalah tanggal ulasan dan ID ulasan sehingga memiliki granularity pada level tiap ulasan.
3. Data Mart Customer RFM
Analisis RFM (Recency-Frequency-Monetary) merupakan teknik segmentasi pelanggan yang dapat memberikan informasi untuk membuat keputusan strategis. Pelanggan akan dibagi kedalam kelompok yang homogen berdasarkan tiga ukuran yaitu:
- Recency, berapa lama sejak pelanggan membeli atau mengunjungi situs
- Frequency, berapa banyak jumlah pembelian atau kunjungan pelanggan
- Monetary, berapa banyak uang yang dikeluarkan oleh pelanggan
Tabel data mart customer RFM (Gambar 1.2.3) dibuat khusus untuk analisis tersebut.
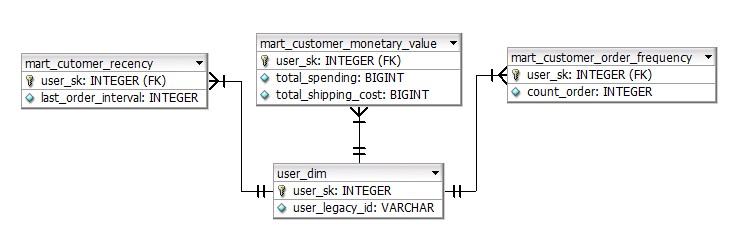
Gambar 1.2.3 Data mart customer RFM ERD
Semua tabel pada data mart customer memiliki dimensi pengguna sehingga level granularity-nya adalah pada setiap pengguna.
ETL Process
Setelah data warehouse selesai dirancang dan dibuat langkah selanjutnya adalah melakukan proses ETL. ETL (Extract-Transform-Load) adalah tahapan untuk mengisi data kedalam data warehouse. Sesuai namanya, ada tiga tahapan dalam proses ETL yaitu:
- Extract, tahap untuk mengambil data dari sumber seperti database, file, atau API
- Transform, melakukan perubahan struktur untuk menyesuaikan dengan kebutuhan pada data warehouse
- Load, memasukkan data kedalam tabel-tabel dalam data warehouse
Proses ETL biasanya menggunakan bantuan tools workflow executor seperti Talend atau Airflow. Saya menggunakan Airflow karena lebih mudah digunakan dan lebih fleksibel. Workflow pada Airflow dapat dibuat menggunakan bahasa pemrograman Python.
Data Analysis
Data warehouse dirancang untuk memudahkan akses terhadap data dan untuk membuat laporan. Akses tersebut sangat krusial pada tahap data analisis ini. Data yang awalnya berasal dari beragam sumber dan dalam beragam format sekarang sudah distandarkan dan diletakkan pada satu repositori yaitu data warehouse.
Analisis data memanfaatkan statistika dan visualisasi grafik untuk menemukan pola atau informasi penting dalam kumpulan data. Informasi-informasi ini adalah basis dari keputusan-keputusan dan rencana strategis yang akan dibentuk.
Pada tahap ini saya melakukan analisis dengan metode yang serupa dengan penelitian formal, yaitu dengan membentuk hipotesis-hipotesis kemudian melihat data untuk membuktikan kebenarannya. Saya memiliki total 5 topik bahasan dalam bentuk pertanyaan-pertanyaan atau business question. Pada setiap business question, terdapat hipotesis dan visualisasi atau analisa statistik untuk membuktikan kebenaran dari setiap hipotesis.
1. Bagaimana Persebaran Pengguna di Indonesia?
Bagi e-commerce, penjual dan pengguna adalah komponen penggerak ekosistem jual-beli. Tanpa salah satu komponen tersebut, tidak akan ada yang namanya e-commerce. Bahkan ukuran benchmark yang secara umum diterima untuk membandingkan performa antara satu e-commerce dengan yang lain.
Pada pertanyaan pertama, saya memiliki 4 hipotesis sebagai berikut:
1.1 Pengguna terkonsentrasi di pulau Jawa
Mengapa pulau Jawa? Populasi, terpadat di Indonesia. Jakarta, ibu kota Indonesia berada di pulau Jawa. Pulau Jawa juga memiliki banyak pelabuhan dan bandar udara internasional. Beberapa alasan tersebut sudah lebih dari cukup bagi saya untuk berasumsi bahwa pengguna e-commerce ini banyak berasal dari pulau Jawa.
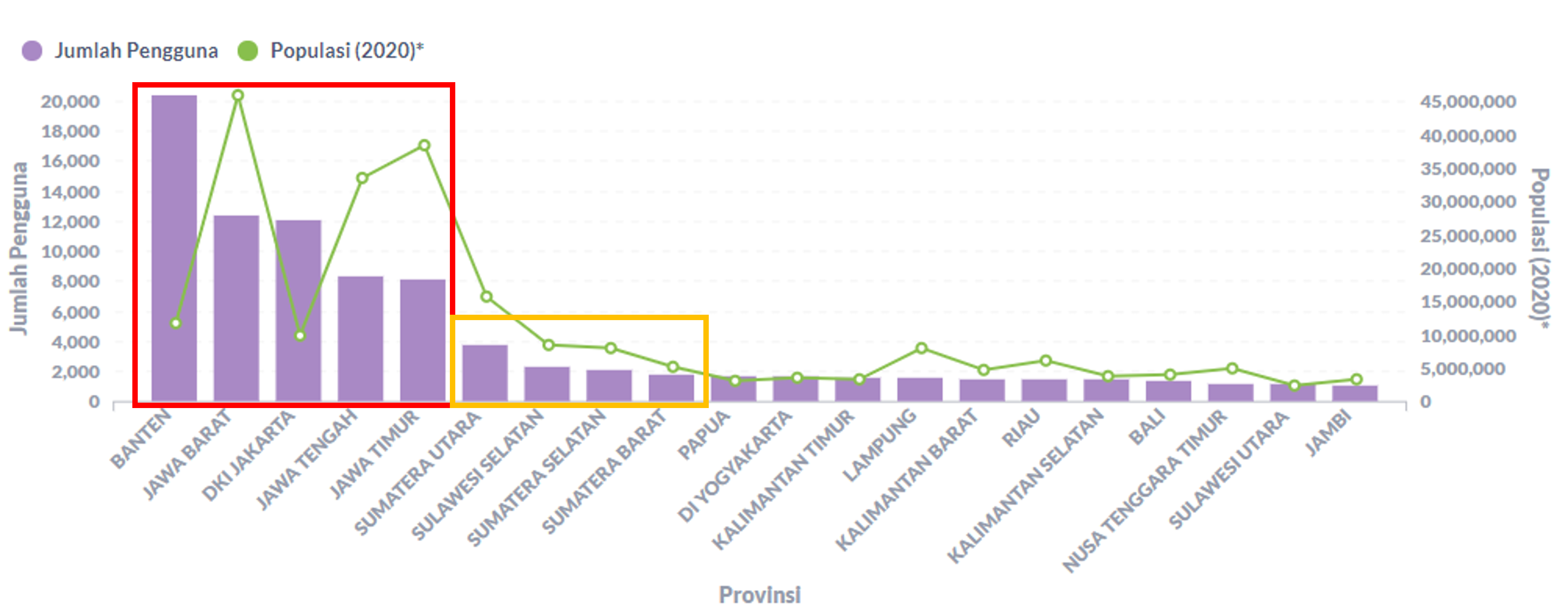
Bagaimana faktanya? Gambar 2.1.1, menunjukkan bahwa 5 provinsi dengan pengguna terbanyak semuanya berasal dari pulau Jawa. Sehingga hipotesis ini terbukti benar.
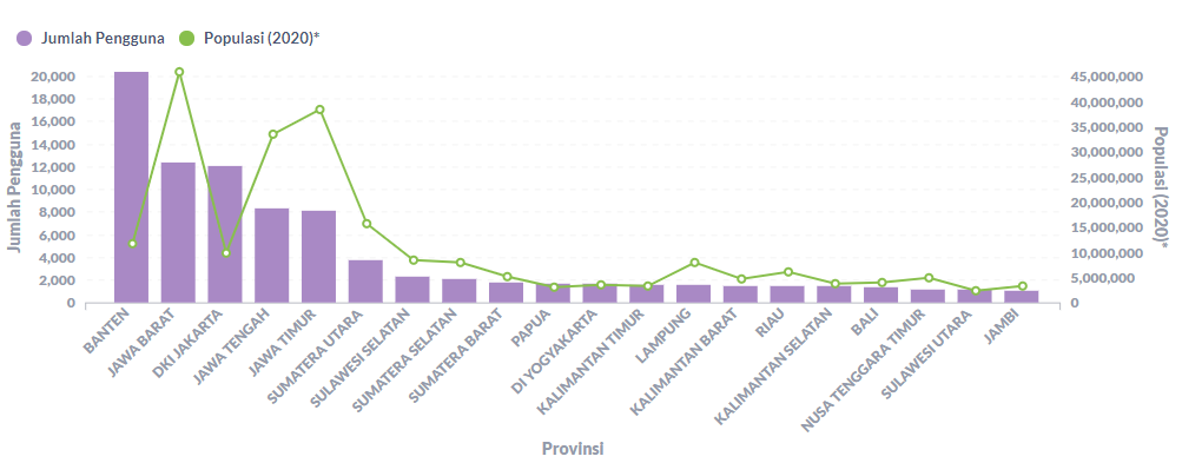
Gambar 2.1.1 Jumlah pengguna terhadap populasi per provinsi (top 20)
1.2 Populasi mempengaruhi jumlah pengguna
Semakin banyak populasi maka jumlah pengguna juga menjadi lebih banyak. Seperti yang terlihat pada hipotesis sebelumnya, pulau Jawa sebagai pulau terpadat di Indonesia memiliki jumlah pengguna yang sangat banyak. Bahkan 5 provinsi dengan pengguna terbanyak semuanya berasal dari pulau Jawa.
Masih merujuk pada Gambar 2.1.1, garis berwarna hijau menunjukkan populasi dan bar berwarna ungu menunjukkan jumlah pengguna pada suatu provinsi. Terlihat di sebelah kanan (ekstrem kecil), jumlah populasi semakin kecil dan diikuti pula dengan jumlah pengguna yang semakin kecil. Sedangkan di sebelah kiri (ekstrem besar), terlihat ada kecenderungan pada provinsi dengan populasi yang tinggi untuk memiliki jumlah pengguna yang tinggi pula. Kesimpulannya, hipotesis ini terbukti benar.
1.3 Penetrasi internet mempengaruhi jumlah pengguna
Keunggulan e-commerce adalah, pengguna hanya perlu mengakses melalui gawainya dan barang yang diinginkan dapat sampai dalam waktu 3 hari saja. Namun perlu juga diperhatikan bahwa “akses” sangat penting.
Akses dalam konteks e-commerce saya bagi kedalam dua bentuk yaitu gawai (piranti keras) dan internet. Hipotesis ini akan menguji dampak ketersediaan akses internet terhadap jumlah pengguna. Sedangkan hipotesis selanjutnya akan menguji dampak keteresediaan gawai.
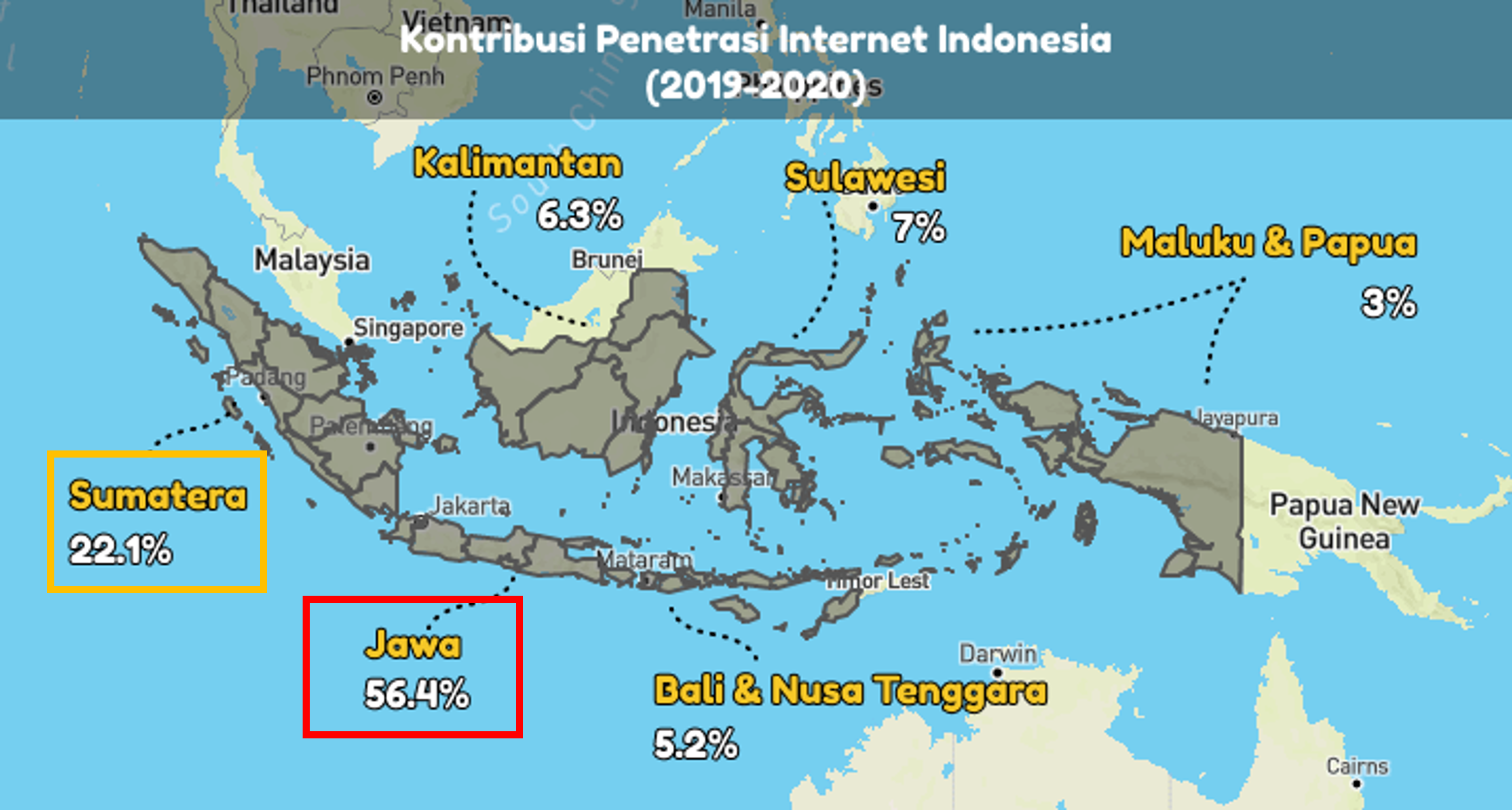
Gambar 2.1.2 Kontribusi penetrasi internet Indonesia
Gambar 1.3.2 Pengguna per provinsi terhadap kontribusi penetrasi internet
Sembilan provinsi dengan jumlah pengguna terbanyak pada e-commerce ini memiliki total kontribusi penetrasi internet sebesar 78.5%. Sudah terlihat bahwa ada kecenderungan dimana semakin banyak penduduk yang dapat mengakses internet, maka semakin banyak pula pengguna pada e-commerce ini.
1.4 Tingkat kepemilikan smartphone mempengaruhi jumlah pengguna
Pada hipotesis sebelumnya telah dibahas mengenai dampak ketersediaan akses internet terhadap jumlah pengguna. Pada hipotesis ini akan menguji dampak kepemilikan gawai terhadap jumlah pengguna.

Gambar 2.1.4 Kepemilikan perangkat elektronik di Indonesia

Gambar 2.1.5 Persentase kepemilikan smartphone di Indonesia
Gambar 2.1.4 menunjukkan perbandingan kepemilikan perangkat elektronik di Indonesia. Pada gambar tersebut terlihat dengan jelas bahwa kepemilikan smartphone jauh lebih tinggi dibandingkan dengan laptop atau komputer.
Tingginya kepemilikan smartphone semakin terlihat jelas pada Gambar 2.1.5, yang menunjukkan bahwa lebih dari 80% penduduk di pulau Jawa dan Sumatera memiliki smartphone, dan lebih dari 40% penduduk di Kalimantan, Sulawesi, Bali, dan Nusa Tenggara juga memiliki smartphone.
Merujuk kepada Gambar 2.1.1 yang menunjukkan bahwa 9 provinsi dengan pengguna terbanyak berasal dari pulau Jawa, Sumatera, dan Sulawesi. Berdasarkan data tersebut kemudian dapat disimpulkan bahwa hipotesis ini benar.
2. Apakah Terdapat Peningkatan Transaksi pada Akhir Pekan?
Akhir pekan adalah momen dimana orang-orang biasanya bersantai dan melakukan aktivitas-aktivitas yang menyenangkan dan menenangkan. Saya memperkirakan akan ada peningkatan transaksi pada akhir pekan karena banyak orang memiliki kecenderungan yang lebih tinggi untuk membuka situs e-commerce pada saat bersantai. Tentu untuk membuktikan hipotesis ini saya perlu melihat pada data yang ada.
2.1 Terdapat peningkatan transaksi pada akhir pekan
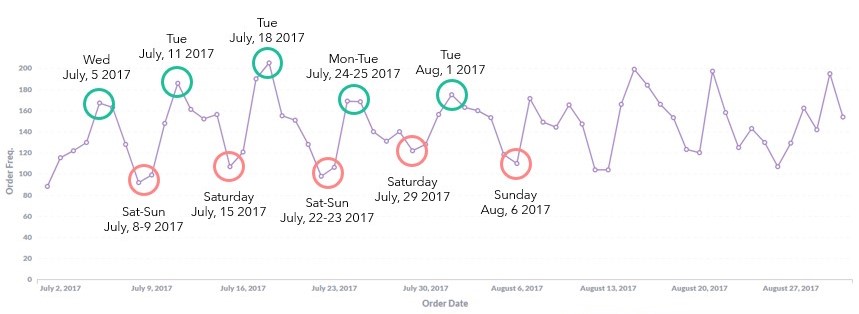
Gambar 2.2.1 Frekuensi transaksi harian pada Juli-Agustus 2017
Data menunjukkan bahwa justru ada penurunan transaksi pada akhir pekan. Inilah pentingnya melakukan analisis pada data. Tanpa melakukan pembersihan data dan visualisasi, informasi seperti ini akan sangat sulit untuk diketahui.
Pada akhirnya hipotesis saya ternyata salah kaprah. Justru pada hari kerja jumlah transaksinya cenderung meningkat. Tentu saya tidak hanya menganalisis pada range bulan Juli hingga Agustus pada satu tahun saja. Range tersebut saya ambil hanya untuk mempermudah dalam visualisasi. Pola yang sama seperti ini dapat dilihat mulai dari bulan April hingga Oktober 2017 dan juga pada tahun 2018.
3. Apa Pengaruh Jumlah Foto Produk Terhadap Tingkat Penjualan?
E-commerce masih merupakan hal baru bagi masyarakat Indonesia. Masyarakat sudah terbiasa berbelanja dengan berinteraksi secara langsung dengan barang yang akan dibeli. Namun melalui e-commerce, interaksi ini tidak mungkin dilakukan. Calon pembeli tidak dapat melihat, menyentuh, dan menilai kualitas barang yang akan dibelinya. Akibatnya, ada potensi penurunan minat untuk membeli barang tersebut.
Menurut Fauzi (2020) dan Li Xin et, al. (2014) foto produk memiliki pengaruh terhadap minat beli konsumen pada e-commerce. Apakah pola ini juga dapat terlihat pada data yang saya miliki? Mari kita lihat hasilnya.
3.1 Jumlah foto berpengaruh positif terhadap jumlah penjualan produk
Pada Gambar 2.3.1, terlihat beberapa kategori dengan produk yang populer cenderung memiliki jumlah foto yang banyak. Namun pada kategori services, furniture, electronics, dan gardening produk yang populer justru memiliki foto yang lebih sedikit daripada produk yang tidak populer.
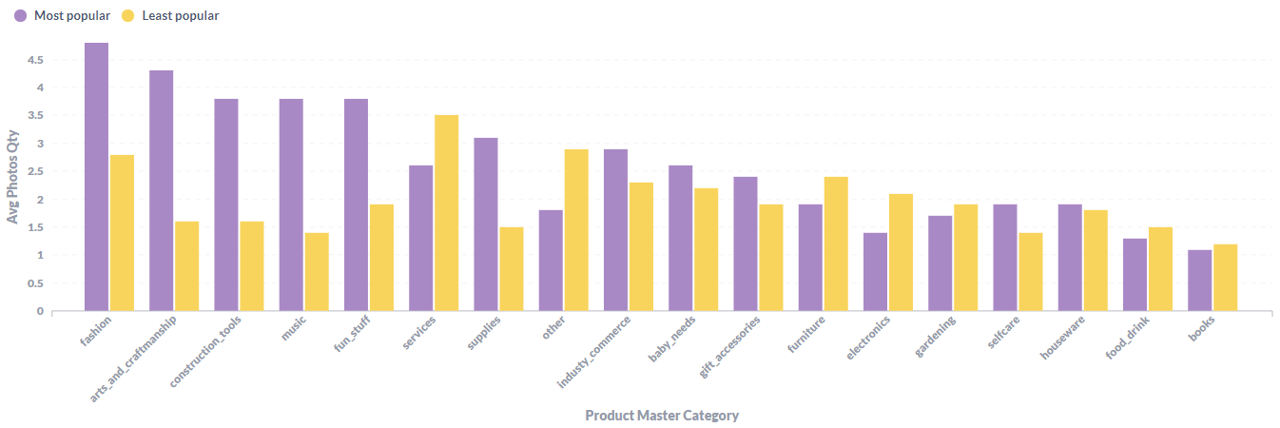
Gambar 2.3.1 Rata-rata jumlah foto terhadap popularitas produk per kategori
Dalam membuktikan hipotesis ini saya menggunakan Pearson’s R Correlation untuk mengetahui hubungan antara satu variabel dengan variabel lain.
Tabel 2.3.1 Correlation matrix
| Photos Qty (all category) | Photos Qty (fashion) | |
|---|---|---|
| Popularity rank by category | -0.091 | -0.165 |
| Order count | 0.009 | 0.094 |
Hasil perhitungan Pearson’s correlation menunjukkan ada hubungan yang sangat lemah antara jumlah foto terhadap popularitas atau jumlah transaksi. Artinya tidak ada korelasi yang signifikan antara jumlah foto terhadap penjualan produk.
4. Apa Pengaruh Penggunaan Voucher Terhadap Kepuasan Pelanggan?
Apa yang kamu rasakan ketika mengetahui kamu hanya perlu membayar separuh harga dari total nilai transaksimu? Tentu bahagia ‘kan. Atas dasar asumsi tersebutlah saya melakukan analisis ini. Saya ingin mengetahui pengaruh penggunaan voucher terhadap kepuasan pelanggan secara ilmiah menggunakan statistika.
Analisis ini menjadi dasar dalam pembuatan model machine learning di tahap data sains. Apabila pengguna merasa lebih puas saat menggunakan voucher, maka lebih baik informasi ini dimanfaatkan untuk meningkatkan frekuensi transaksi dari pengguna.
Informasi ini juga dapat digunakan untuk meningkatkan nilai transaksi. Kamu pernah mendapat voucher yang hanya dapat digunakan apabila telah membeli minimal Rp. 100.000? Ya, seperti itu contoh sederhananya.
Pada analisis ini saya menggunakan Z-test untuk mengetahui apakah ada perbedaan kepuasan ketika pengguna menggunakan voucher dibandingkan tidak menggunakan voucher. Hipotesis pada analisis ini yaitu:
- \(H_0 \Rightarrow \bar{x}_v \approx 4.10\).
- \(H_a \Rightarrow \bar{x}_v \neq 4.10\).
Tabel 2.4.1 Parameter dan nilai Z-test
| Parameter | Nilai |
|---|---|
| Avg. Feedback (\(\bar{x}_0\)) | 4.10 |
| Sample size | 250 |
| Sample mean | 4.09 |
| Sample STDDEV | 1.36 |
| Confidence level | 99% |
| Significance level | 0.01 |
Tabel 2.4.2 Hasil kalkulasi Z-score
| Hasil | Nilai |
|---|---|
| Z-score | -0.11 (Approx.) |
| P-value | 0.91241 (Approx.) |
Hasil kalkulasi Z-score menunjukkan bahwa tidak ada perbedaan nilai ulasan pada transaksi menggunakan voucher terhadap transaksi tanpa voucher. Artinya, menggunakan voucher atau tidak ternyata tidak memiliki efek terhadap kepuasan pelanggan.
Sedikit kontras dan diluar dari apa yang saya harapkan. Namun analisis ini tidak cukup untuk membuktikan apakah penggunaan voucher sama sekali tidak memiliki dampak terhadap kepuasan pelanggan. Saya hanya menganalisis pada satu variabel saja, ada kemungkinan variabel lain yang mempengaruhi kepuasan pelanggan secara lebih besar. Misalnya keterlambatan pengiriman, respon penjual yang tidak ramah, kemasan produk kurang rapi, produk cacat, dan lainnya.
5. Bagaimana Hasil Analisis RFM Pelanggan?
Tim marketing perlu mengetahui seluk beluk pelanggan pada e-commerce untuk dapat menghasilkan strategi pemasaran yang baik. Salah satu bentuk analisis pelanggan adalah melakukan segmentasi berdasarkan RFM.
Seperti yang sudah dijelaskan pada bagian data engineer sebelumnya, pelanggan akan dibagi kedalam kelompok-kelompok homogen berdasarkan tiga ukuran yaitu:
- Recency, berapa lama sejak pelanggan membeli atau mengunjungi situs
- Frequency, berapa banyak jumlah pembelian atau kunjungan pelanggan
- Monetary, berapa banyak uang yang dikeluarkan oleh pelanggan
5.1 Mayoritas pelanggan hanya pernah melakukan satu kali transaksi
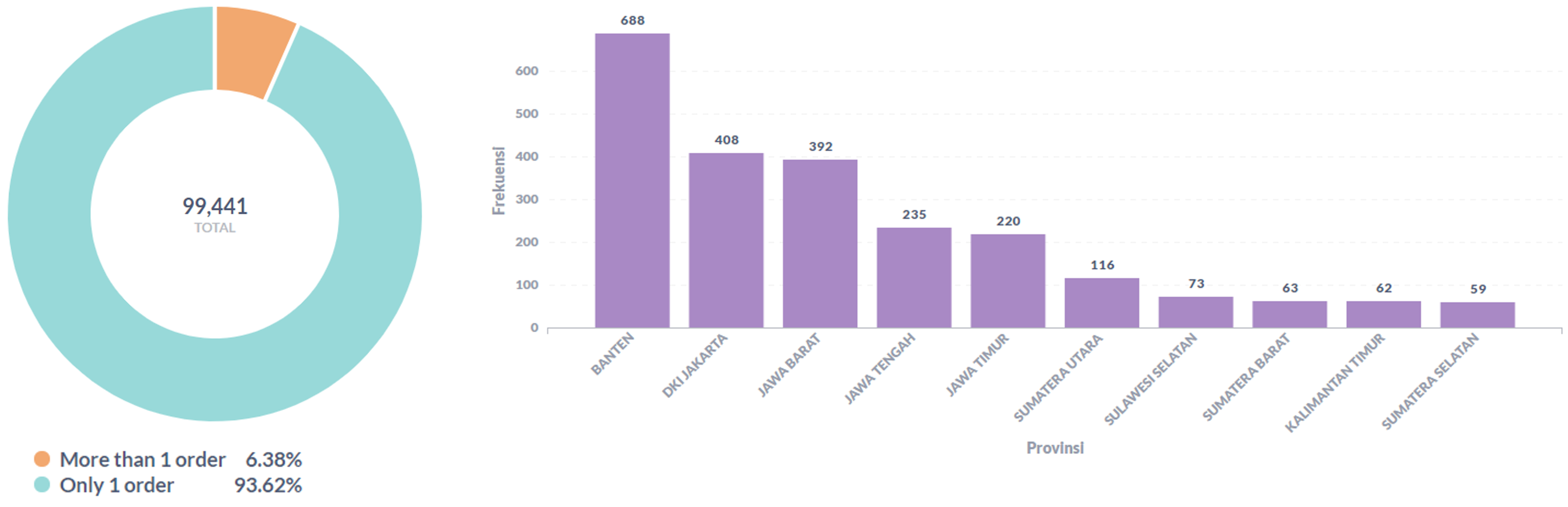
Gambar 2.5.1 Perbandingan jumlah belanja pengguna
Sebanyak 93,6% dari pengguna hanya pernah bertransaksi sebanyak satu kali. Pengguna yang bertransaksi lebih dari satu kali terbanyak berasal dari Banten, DKI Jakarta, dan Jawa Barat. Berdasarkan hasil tersebut maka hipotesis ini terbukti benar.
Data Science
Setelah melakukan analisis menggunakan statistika dan visualisasi, pada bagian ini saya akan melakukan analisis menggunakan bantuan komputer. Melalui model machine learning saya dapat melakukan analisa prediktif untuk membantu dalam pengambilan keputusan.
Pada bagian ini saya akan membuat dua jenis model yaitu supervised dan unsupervised. Model pertama untuk melakukan prediksi terhadap penjualan produk menggunakan metode supervised learning. Model kedua digunakan untuk melakukan segmentasi pelanggan menggunakan metode unsupervised learning.
Sales Prediction
Analisa yang tidak boleh terlewatkan pada e-commerce adalah analisa penjualan. Prediksi penjualan dapat bermanfaat untuk menyusun strategi dalam menghadapi perubahan permintaan.
Pemodelan machine learning untuk prediksi penjualan diawali dengan Exploratory Data Analysis kemudian pembuatan model dasar (baseline model) sebelum akhirnya dilanjutkan dengan menggunakan beberapa algoritma.
Exploratory Data Analysis
Tahap exploratory data analysis (EDA) merupakan bagian analisis yang diperlukan untuk menentukan variabel yang tepat untuk menjadi fitur, menentukan bagaimana proses preprocessing akan dilakukan, dan mengetahui pilihan algoritma yang tepat untuk melakukan training model. Analisis pada tahap ini juga dapat menentukan ukuran atau metric yang tepat untuk mengetahui performa model yang telah dilatih.
Pada bagian ini saya melakukan analisis statistika sederhana untuk mengetahui persebaran dan konsentrasi penjualan. Data yang saya gunakan memiliki range dari tahun 2016 hingga 2018 sebanyak 634 baris data (Tabel 3.1.1).
Tabel 3.1.1 Statistik dari 5 variabel timeseries
| Year | Month | Week Num in Year | Date | Day of Week | |
|---|---|---|---|---|---|
| count | 634 | 634 | 634 | 634 | 634 |
| min | 2016 | 1 | 1 | 1 | 1 |
| max | 2018 | 12 | 53 | 31 | 7 |
| null | 0 | 0 | 0 | 0 | 0 |
Tabel 3.1.2 Statistik dari variabel jumlah transaksi
| Count Order | |
|---|---|
| count | 634 |
| mean | 156.84 |
| std | 94.22 |
| min | 1 |
| 25% | 96 |
| 50% | 148 |
| 75% | 215.7 |
| max | 1176 |
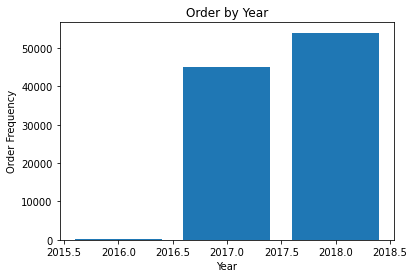
Gambar 3.1.1 Grafik jumlah transaksi per tahun
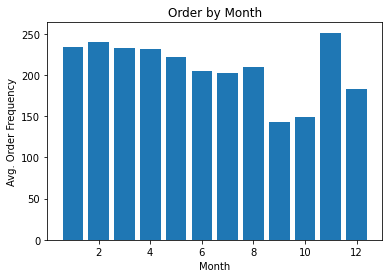
Gambar 3.1.2 Grafik rata-rata jumlah transaksi per bulan
Rata-rata jumlah penjualan pada satu hari adalah sekitar 156 transaksi, dengan standar deviasi yaitu ~95 transaksi. Terlihat ada pencilan pada transaksi dengan jumlah 1176 (max). Mengetahui adanya pencilan tersebut, metric mean squared error tidak tepat untuk digunakan karena berpotensi menghasilkan nilai error yang sangat tinggi.
Baseline Model
Sebelum membuat model menggunakan supervised learning, model dasar sederhana atau model heuristic untuk mengevaluasi performa model-model yang lainnya. Model ini digunakan untuk mengetahui apakah model machine learning yang dibuat cukup baik untuk diterima.
Model dasar melakukan prediksi penjualan dengan menggunakan nilai rata-rata dari data. Hasil evaluasi model ditampilkan pada Tabel 3.1.3.
Tabel 3.1.3 Evaluasi model baseline
| Error Metric | Error |
|---|---|
| Mean squared error | 8864.3 |
| Root mean squared error | 94.1 |
| Median absolute deviation | 59.8 |
| Mean absolute error | 70.6 |
Multilayer Perceptron Regression
Model pertama menggunakan multilayer perceptron (MLP), salah satu bentuk neural network dengan semua node pada dua layer yang bersebelahan saling terhubung dan disebut juga dengan dense neural network.
Hasil hyperparameter tuning pada Tabel 3.1.4 menunjukkan jumlah layer yang optimal adalah 3 layer. Sebanyak 100 node berada pada layer pertama, 30 node pada layer kedua, dan 10 node pada layer ketiga.
Tabel 3.1.4 Hasil hyperparameter tuning model MLP
| Parameter | Best Value |
|---|---|
| Hidden layer | (100, 30, 10) |
| Activation | relu |
| Solver | lbfgs |
| Learning rate init | 0.1 |
Setelah melakukan training menggunakan MLP dihasilkan model yang terlalu overfit. Artinya, model tersebut dapat mereplikasi data latih dengan sangat baik, terlampau baik bahkan, hingga error yang terdapat pada data juga turut direplikasi. Hasilnya model ini dapat memprediksi data latih dengan sangat baik namun gagal untuk memprediksi data yang tidak pernah dilihat sebelumnya. Visualisasi dari kondisi ini dapat terlihat pada Gambar 3.1.3.
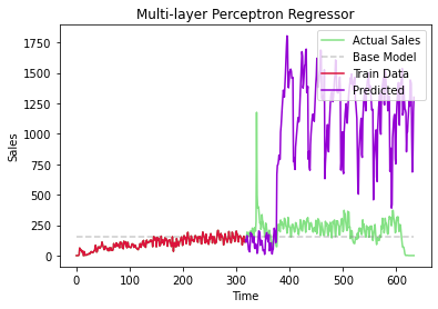
Gambar 3.1.3 Evaluasi model MLP
Tabel 3.1.5 menunjukkan hasil evaluasi model ini. Apabila dibandingkan dengan model baseline sebelumnya, maka dapat diambil kesimpulan bahwa model ini lebih buruk.
Tabel 3.1.5 Evaluasi model MLP
| Error Metric | Value |
|---|---|
| Mean squared error | 256694 |
| Root mean squared error | 305 |
| Median absolute deviation | 101.15 |
| Mean absolute error | 228.83 |
Support Vector Regression
Tabel 3.1.6 menunjukkan hasil hyperparameter tuning dengan nilai parameter untuk menghasilkan model yang paling optimal.
Meski model yang dihasilkan telah optimal namun model ini tidak memiliki performa yang baik. Model tersebut memiliki sifat underfit yang ditandai dengan ketidakmampuan untuk mempelajari pola dari data latih. Kondisi ini dapat terlihat jelas pada Gambar 3.1.4 yang menunjukkan garis berwarna merah tidak berada pada posisi yang sama dengan garis hijau (nilai penjualan sebenarnya).
Tabel 3.1.6 Hasil hyperparameter tuning model SVR
| Parameter | Best Value |
|---|---|
| C (regularization parameter) | 2 |
| Tolerance (stopping criteria) | 0.05 |
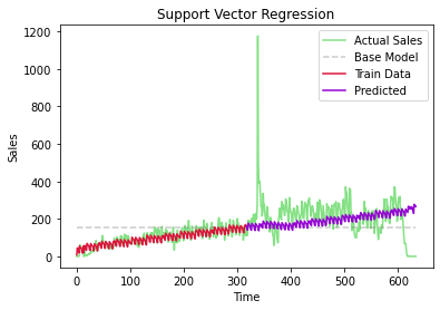
Gambar 3.1.4 Evaluasi model SVR
Tabel 3.1.7 Evaluasi model SVR
| Error Metric | Value |
|---|---|
| Mean squared error | 8017.3 |
| Root mean squared error | 76.44 |
| Median absolute deviation | 37.25 |
| Mean absolute error | 51.5 |
Meski model ini bersifat underfit, apabila dilihat dari hasil ukuran error maka model ini lebih baik daripada model baseline.
Random Forest Regression
Model ketiga adalah random forest yang merupakan jenis model ensemble. Random forest terdiri dari beberapa decision tree yang dibuat dengan parameter tertentu secara acak. Biasanya decision tree yang dihasilkan akan memiliki batas jumlah daun untuk meminimalisir kemungkinan overfitting.
Setelah melakukan hyperparameter tuning dihasilkan parameter yang optimal pada Tabel 3.1.8.
Tabel 3.1.8 Hasil hyperparameter tuning model random forest
| Parameter | Best Value |
|---|---|
| Criterion | mae |
| n_estimators | 300 |
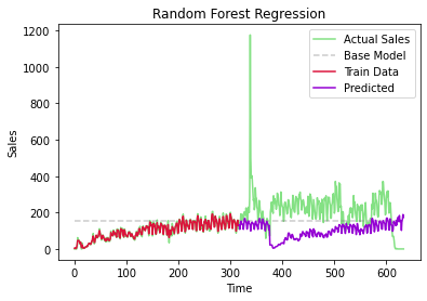
Gambar 3.1.5 Evaluasi model RF
Model ini juga memiliki nasib yang sama seperti model MLP sebelumnya. Parameter yang optimal menghasilkan model yang sedikit overfit terhadap data latih. Gambar 3.1.5 menunjukkan garis merah berada pada posisi yang hampir sama dengan garis hijau (jumlah penjualan sebenarnya), namun ketika model memprediksi data baru (garis ungu) hasilnya tidak sesuai dengan jumlah penjualan yang sebenarnya.
Hasil evaluasi model ini ditampilkan pada Tabel 3.1.9.
Tabel 3.1.9 Evaluasi model RF
| Error Metric | Value |
|---|---|
| Mean squared error | 11055.5 |
| Root mean squared error | 92.5 |
| Median absolute deviation | 66.9 |
| Mean absolute error | 72.4 |
Customer Segmentation
Segmentasi pelanggan bermanfaat untuk keperluan pemasaran. Hasil analisis pelanggan pada poin 2.5.1 menunjukkan bahwa selama dua tahun, hanya 6,4% dari seluruh pengguna e-commerce melakukan transaksi lebih dari satu kali. Perlu adanya strategi pemasaran untuk meningkatkan jumlah transaksi pengguna.
Strategi yang saya tawarkan adalah pemberian voucher gratis ongkir kepada pelanggan yang memenuhi kriteria tertentu. Misalnya, pelanggan yang sudah lama tidak melakukan transaksi, pelanggan yang jarang melakukan transaksi, dan pelanggan yang nilai transaksinya rendah.
Segmentasi pelanggan menggunakan machine learning dapat bermanfaat untuk membagi pelanggan kedalam kelompok-kelompok tertentu. Kemudian dari kelompok tersebut dapat ditentukan mana yang tepat untuk mendapatkan voucher gratis ongkir.
Exploratory Data Analysis
Sama seperti pada bagian sales prediction sebelumnya, tahapan pemodelan diawali dengan analisis data menggunakan statistika dan grafik. Tahap EDA ini penting untuk mengetahui sifat dari data dan untuk menentukan algoritma, metric, dan pemrosesan data yang tepat digunakan.
Tabel 3.2.1 Statistik fitur RFM
| Total Spending | Count Order | Last Order Days | |
|---|---|---|---|
| Count | 94983 | 94990 | 94990 |
| Mean | 142074.8 | 1.033 | 288.349 |
| Std | 216076 | 0.210 | 153 |
| Min | 8500 | 1 | 45 |
| 25% | 47900 | 1 | 164 |
| 50% | 89890 | 1 | 269 |
| 75% | 155000 | 1 | 397 |
| Max | 13440000 | 16 | 774 |
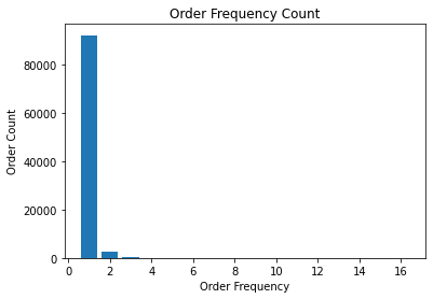
Gambar 3.2.1 Distribusi jumlah transaksi per pengguna
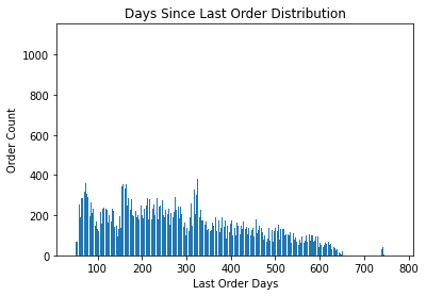
Gambar 3.2.2 Distribusi n hari terakhir transaksi
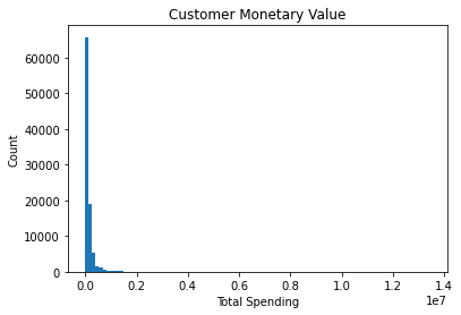
Gambar 3.2.3 Total pengeluaran pelanggan
Baseline Model
Sebelum melakukan training pada model unsupervised saya membuat model baseline sebagai acuan performa model yang selanjutnya.
Model dibuat dengan melakukan segmentasi secara manual. Pertama, saya mendefinisikan ranking pada RFM sesuai Tabel 3.2.2. Selanjutnya, pelanggan dibagi kedalam segmen-segmen sesuai kriteria pada Tabel 3.2.3.
Tabel 3.2.2 RFM Tier
| Recency | Frequency | Monetary |
|---|---|---|
| R-Tier-1 (most recent) | F-Tier-1 (most frequent) | M-Tier-1 (highest spend) |
| R-Tier-2 | F-Tier-2 | M-Tier-2 |
| R-Tier-3 | F-Tier-3 | M-Tier-3 |
| R-Tier-4 | F-Tier-4 | M-Tier-4 |
Tabel 3.2.3 Segmentasi pelanggan
| Recency | Frequency | Monetary | Customer Segment |
|---|---|---|---|
| 1-2 | 1-4 | 1-2 | High-spending Active Customer** |
| 1-2 | 1-4 | 3-4 | Low-spending Active Customer* |
| 3-4 | 1-4 | 1-2 | Churned High-spending Customer** |
| 3-4 | 1-4 | 3-4 | Churned Low-spending Customer* |
Segmentasi tersebut mengelompokkan pengguna yang memiliki sifat-sifat serupa kedalam 4 kelompok. Hasil pengelompokan ini dapat dilihat pada visualisasi Gambar 3.2.4 dan Gambar 3.2.5. Nilai evaluasi silhouette score diperoleh -11.
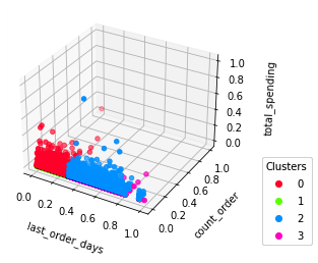
Gambar 3.2.4 Baseline model cluster result 3D
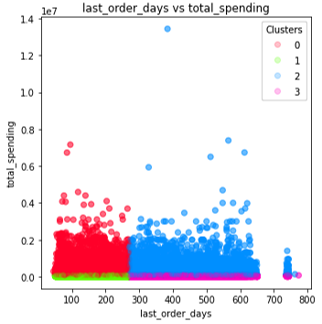
Gambar 3.2.5 Baseline model cluster result 2D
K-Means Clustering
Model K-Means melakukan clustering dengan cara memilih sembarang titik secara acak kemudian menghitung jarak dari titik tersebut ke data-data yang paling dekat. Centroid yang awalnya acak tersebut kemudian berpindah menuju ke pemusatan data sehingga menghasilkan jarak antar data (within cluster distance) yang paling minimal. Setelah beberapa iterasi atau ketika tidak ada perubahan yang signifikan pada jarak antar data dalam cluster maka model dikatakan converge.
Saintis data perlu mengatur secara manual jumlah K (cluster) yang ingin diperoleh. Salah satu cara untuk mengetahui nilai K yang optimal adalah menggunakan elbow method. Gambar 3.2.6 menunjukkan nilai within cluster distance terhadap jumlah cluster. Dapat diketahui bahwa perubahan within cluster distance yang tidak lagi signifikan berada pada K = 4. Sehingga pada model ini saya menggunakan 4 cluster. Hasil hyperparameter tuning ditunjukkan pada Tabel 3.2.4.
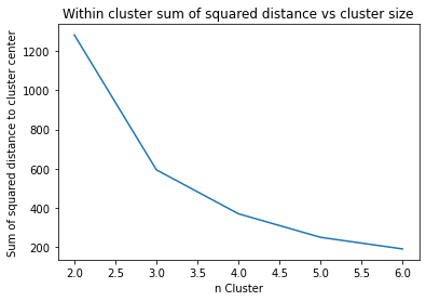
Gambar 3.2.6 Pengaruh nilai K terhadap jarak antar data dalam cluster
Tabel 3.2.4 K-Means hyperparameter tuning
| Parameter | Best Value |
|---|---|
| Init | K-Means++ |
| Tolerance (for convergence criteria) | 0.03 |
Parameter tersebut menghasilkan model dengan 4 cluster yang terlihat pada Gambar 3.2.7 dan 3.2.8. Hasil model ini cenderung memisahkan data berdasarkan fitur “last order days”. Nilai evaluasi disajikan pada Tabel 3.2.5.
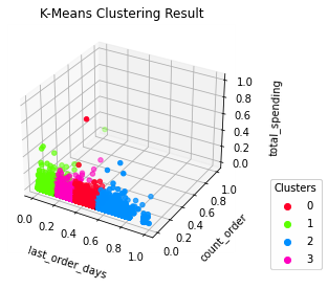
Gambar 3.2.7 K-Means cluster result 3D
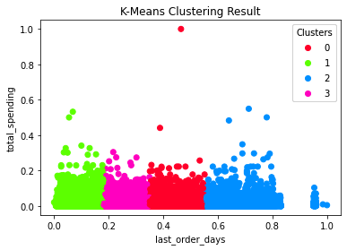
Gambar 3.2.8 K-Means cluster result 2D
Tabel 3.2.5 Evaluasi K-Means
| Score | Value |
|---|---|
| Silhouette score | 0.53 |
| Within cluster sum of squared distance | 370.3 |
K-Medoids Clustering
Serupa dengan model K-Means, K-Medoids juga memilih centroid atau dalam kasus ini adalah medoids secara acak pada awal iterasi. Apa bedanya centroid dengan medoid? Centroid adalah suatu titik pada ruang dimensi yang menjadi pusat cluster, sedangkan medoid adalah data point yang menjadi pusat cluster. Sederhananya, centroid bukan merupakan bagian dari data sedangkan medoid merupakan bagian dari data.
Pada model ini, saintis data juga perlu menentukan jumlah K secara manual. Menggunakan metode yang sama dengan K-Means, diperoleh nilai K yang optimal adalah K = 6 (Gambar 3.2.9). Hasil hyperparameter tuning ditunjukkan pada Tabel 3.2.6.
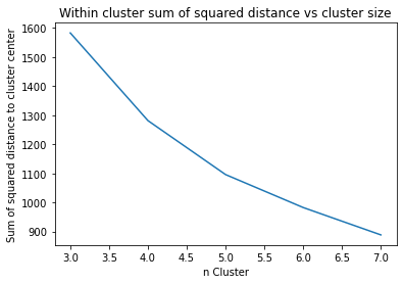
Gambar 3.2.9 Pengaruh nilai K terhadap jarak antar data dalam cluster
Tabel 3.2.6 Hyperparameter tuning K-Medoids
| Parameter | Best Value |
|---|---|
| Distance metric | euclidean |
| init | K-Medoids++ |
Menggunakan parameter tersebut menghasilkan model dengan 6 cluster. Masih sama dengan model K-Means sebelumnya, model ini cenderung membagi kelompok berdasarkan fitur “last order days”. Terlihat pada Gambar 3.2.10 dan 3.2.11, model membentuk cluster yang hampir homogen. Diperoleh hasil evaluasi pada Tabel 3.2.7.
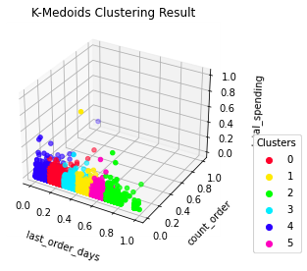
Gambar 3.2.10 K-Medoids cluster result 3D
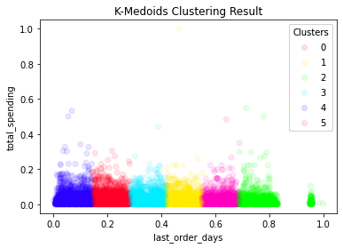
Gambar 3.2.11 K-Medoids cluster result 2D
Tabel 3.2.7 Evaluasi model K-Medoids
| Score | Value |
|---|---|
| Silhouette score | 0.43 |
| Within cluster sum of squared distance | 982.4 |
Hierarchical Agglomerative Clustering
Model hierarchical agglomerative membentuk cluster dengan pendekatan bottom-up. Data-data individual yang berdekatan akan dikelompokkan kedalam satu cluster. Kemudian cluster-cluster yang saling berdekatan akan dilebur menjadi satu cluster yang lebih besar. Proses ini dilakukan terus-menerus hingga terbentuk satu cluster yang memuat seluruh data. Hasil peleburan ini dapat divisualisasikan dalam bentuk dendogram seperti pada Gambar 3.2.12.
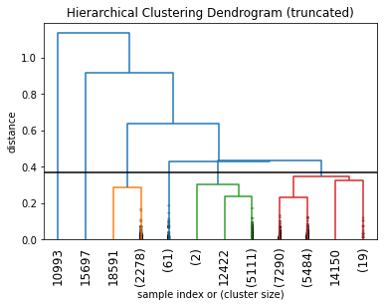
Gambar 3.2.12 Hierarchical clustering dendogram
Tabel 3.2.8 Hyperparameter tuning untuk model hierarchical
| Parameter | Best Value |
|---|---|
| Linkage method | Median |
| Linkage metric | Euclidean |
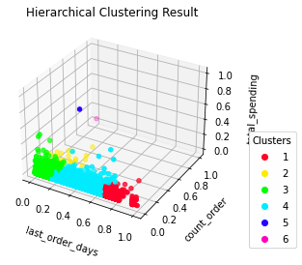
Gambar 3.2.13 Hierarchical cluster result in 3D
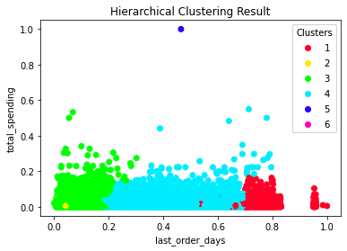
Gambar 3.2.14 Hierarchical cluster result in 2D
Tabel 3.2.9 Evaluasi model hierarchical agglomerative
| Score | Value |
|---|---|
| Silhouette score | 0.31 |
Model yang dilatih dengan parameter pada Tabel 3.2.8 menghasilkan 6 cluster yang sangat heterogen. Berbeda dengan model K-Means dan K-Medoids, model ini tidak hanya membagi pelanggan berdasarkan fitur “last order days” saja. Dua fitur lainnya juga berperan pada model ini. Namun akibatnya, karena terdapat dua pencilan pada data maka ada dua cluster yang hanya memiliki satu anggota.
Summary
Pelanggan yang hanya melakukan transaksi sebanyak satu kali saja tentu memiliki alasan. Sebagai calon saintis data, teknologi dapat membantu dalam momen seperti ini. Rancangan strategi dan target yang tepat diharapkan mampu meningkatkan jumlah transaksi pelanggan.
Menggunakan machine learning kita juga dapat melihat masa depan dengan lebih yakin. Menggunakan data historikal untuk membantu mengetahui kondisi pada masa yang akan datang.
Sekian artikel saya terkait analisis data e-commerce. Kritik dan saran dapat disampaikan melalui email atau yang lebih keren melalui LinkedIn.