Future Data Track pt. 2: Data Engineer
Background
In order to provide data for analysis, reporting, decission making, ML training, and etc.; the first thing to do is to construct an architecture for data repository with data warehousing technique. By creating this data warehouse, we can collect and integrate data from many different sources. Data warehouse provide a uniform and formalized data schemas and semantics for the whole organization.
Data from different sources needs to be collected periodically and ideally automatically. This step is part of the Extract step of ETL (Extract, Transform, and Load). After the data is collected, we need to transform or clean them. Then the transformed data is loaded to a data repository that will be accessed by the end user.
In this blog post we will cover the overview of data engineering steps of preparing Mobile App Review data for analysis.
Overview of Data Pipeline
Data pipeline is a means to move data from its source to the destination. Along the way, data is transformed and optimized for it to be analyzed and to gain insights from it. It is important to have a bird-eye view of the pipeline to understand the movement of data across different data repository.
The image below shows the overview of the data pipeline that we created. From the furthest left side is the source of the data, coming from external source scraped using a library. To its right skipping the subsystem, is the main ETL executor; the Airflow machine. In this pipeline we used Airflow as our workflow executor, for detailed instruction on Airflow installation and configuration please refer to my blog post, Running Airflow in Docker.
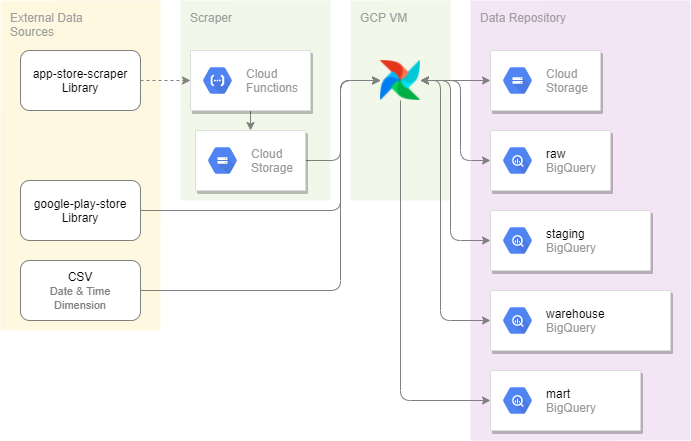
Figure 2.1 Overview of Data Pipeline
Finally at the rightmost is the main data repository. There are several layers of them that will be detailed in the upcoming section. The data repository mainly uses Google BigQuery. However we also used Google Cloud Storage (GCS) for temporary data storage.
Data Sources
Our data comes from external sources that is captured using a scraping library. The two library used, referring back to the pipeline diagram from previous section, are google-play-scraper and app-store-scraper. The former is a Python library which means we can use it directly in Airflow, the later however is written in Javascript. The app-store-scraper library needs a subsytem to execute them, this explains the need of the blue area between data source and our VM. Both of the library used supports scraping review and app details data, and both of which are collected.
Reviews & App Details
Reviews are important publicly available metrics of an ecommerce performance. Users will look at the app reviews to compare and understand their individual advantages and disadvantages. Business can also make improvement on their services or apps by analyzing the user-generated reviews. App details data such as updated date, release note, updated version, and etc.; are also collected to enrich the reviews.
For detailed explanation of scraping reviews and app details data from those library please refer to Scraping App Review Data.
Tweets
We also not only planned to but already created a custom library to scrape Twitter tweets, but due to several technical problems we decided to give up on this. The main problem is caused by Chrome browser crashing when it’s started by Selenium. We have identified the issue and possibly obtained the methods to fix it but since the deadline is coming closer really fast, we didn’t want to waste our time here.
We haven’t analyzed how much impact the tweets data will have to our analysis if we managed to collect it. Nayebi, M. et al. (2018)1, concluded that we could gain more information regarding users’ request through social media discussion such as tweets. The research of Nayebi is actually the basis that inspires us to collect tweets as additional data.
Data Cleaning
Due to difference in data types, schemas and semantics from different data sources we’ll have to prepare our data by transforming and unifying them. This step is part of the Transform step in ETL.
There are several things we do in this step, those are:
- Data type casting
- Schema tranformation and unification
- Data deduplication
Those processing are applied to both reviews and app details data. The detail of our data tranformation is explained in this post: Scraping App Review Data.
Data Warehouse Design
Data warehouse stores denormalized data that are optimized for data reading. In data warehouse there are two frequently used schema, star schema and snowflake schema. A star schema is a collection of dimension tables and one or more fact tables 2,3. The fact table contains transactional information while dimension table consists only master data 2,3,4,5. A snowflake schema is a variant of the star schema6. In the snowflake schema, dimension tables are normalized in multiple related tables.
The data warehouse are designed using dimensional modelling with star schema. The ERD below shows the dimensional model of our data warehouse.

Figure 5.1 Data Warehouse Dimensional Model
Please refer to my previous blog post for more in-depth data warehouse architecture of Mobile App Review analysis.
Data Marts
Data warehouse solves the problem of uniforming the structure of organizational data. However, data in the form of facts and dimensions are confusing for end users. They are forced to learn the warehouse architecture to access the data that they want.
To make accessing it easier, we can create tables or views as data mart. This data layer provides easier access to data stored in data warehouse.
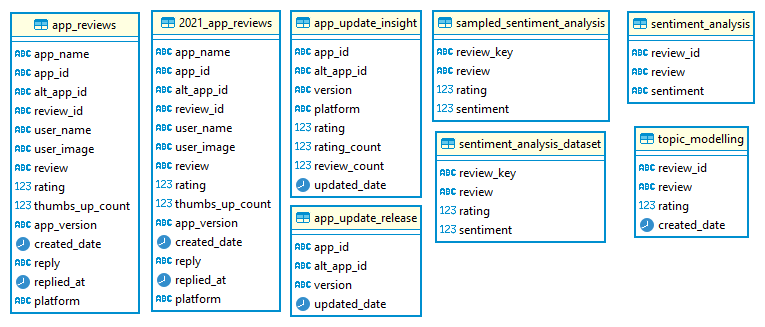
Figure 6.1 Tables in Datamart
Table app_reviews and 2021_app_reviews contains app review and were used in dashboard tools. Our main analysis uses this table, acompanied by the app_update_release and app_update_insights table.
Besides doing analysis and reporting with dashboarding tools, we also trained a sentiment analysis model using sentiment_analysis_dataset and sampled_sentiment_analysis as our training data. The predicted sentiment is stored in the sentiment_analysis table.
We also trained another machine learning model to predict the topic of a review. To train it, we used the table topic_modelling.
Summary
The data pipeline that we designed uses Airflow as the workflow executor. The data are collected from external sources using scraping library. We uses several layers of data repository: raw, staging, warehouse, and datamart.
Data cleaning steps consisting of data type casting, schema transformation and unification, and data deduplication.
In data warehouse we use dimensional modelling with star schema. We produced two fact tables and five dimension tables.
To provide easier access to our data, we created several tables in datamart layer.
References
[1] Nayebi, M., Cho, H., & Ruhe, G. (2018). App store mining is not enough for app improvement. In Empirical Software Engineering (Vol. 23, Issue 5). Empirical Software Engineering. https://doi.org/10.1007/s10664-018-9601-1
[2] Dedić, N., & Stanier, C. (2016). An evaluation of the challenges of multilingualism in data warehouse development.
[3] Cios, K. J., Swiniarski, R. W., Pedrycz, W., & Kurgan, L. A. (2007). The knowledge discovery process. In Data Mining (pp. 9-24). Springer, Boston, MA.
[4] Kimball, R., Ross, M., Thorthwaite, W., Becker, B., & Mundy, J. (2008). The data warehouse lifecycle toolkit. John Wiley & Sons.
[5] Jensen, C. S., Pedersen, T. B., & Thomsen, C. (2010). Multidimensional databases and data warehousing. Synthesis Lectures on Data Management, 2(1), 1-111.
[6] Kamaurya, P. (2021). Snowflake Schema in Data Warehouse Model. https://www.geeksforgeeks.org/snowflake-schema-in-data-warehouse-model/ [Archived 18 Feb, 2022]